Scaling Cloud IDE Provisioning by 5x: From 5K to 25K Workspaces in One Region
February 21, 2026

Business Context
AI has fundamentally changed how software is built, yet many hiring processes remain stuck in the past - favoring abstract puzzles over the real-world skills of debugging and AI-assisted development. This disconnect means companies often overlook top-tier talent.
At HackerRank, this shift increased adoption of next-gen hiring, where cloud-based IDEs are central to how candidates are evaluated.
While our infrastructure was good at 5,000 concurrent workspaces just a few years ago, the surge in high-stakes, large-scale hiring events meant we had to radically rethink our regional capacity.
Problem Statement
While scaling projects infrastructure at HackerRank, we hit a hard performance ceiling at 5,000 concurrent workspaces per region.
Rather than chasing an arbitrary target, our journey was driven by solving real-world reliability and throughput failures that surfaced under peak event loads.
This post explores the bottlenecks we uncovered as engineers and the architectural shifts required to break through that ceiling, keeping the focus on high-level patterns rather than granular internal service details.
Understanding the 5K Workspace Capacity Limit
At this scale, provisioning is not just spinning up more VMs. It is a distributed systems coordination problem:
- Cloud API rate limits and quotas
- VM creation throughput
- State update overhead
- Database connection pressure
- Git repo setup bottlenecks
- NFS metadata IOPS overhead
- Tail-latency spikes during bursts
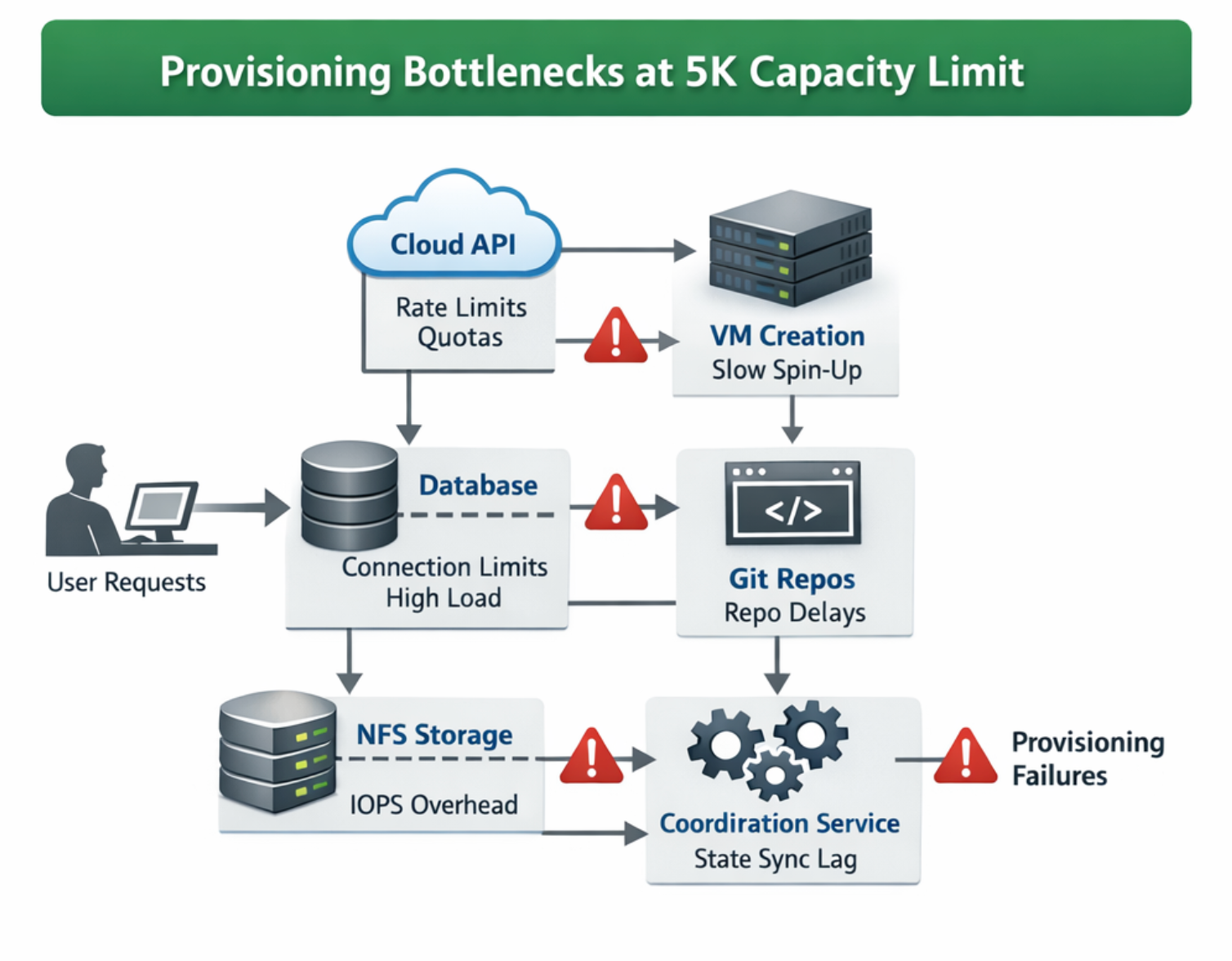
The key lesson: Optimizing one service in isolation would not move the overall ceiling.
Insight 1: Remove External Constraints First
Before service-level tuning, we increased infra headroom so we would not get throttled early.
Quota and capacity changes
- Increase Read requests per region/min:
15,000 - Increase Write requests per region/min:
16,500 - Increase Queries per region/min:
15,000 - Increase Instance capacity per single VPC:
50,000 - Increase Private IP allocation:
65,000 - Expanded primary private IP range to
/16(65,536 IPs)
This removed the first hard blocker and gave us room to optimize safely.
Insight 2: Bulk APIs Change the Scaling Curve
Single-resource operations were too expensive at high concurrency.
Bulk VM creation
We moved VM creation to bulk insert APIs to reduce control-plane overhead in each cloud provider. This was a game-changer for provisioning throughput.
Bulk route updates
After bulk creation, we used Redis pipelines for route entry insertion in batches instead of one round trip per route.
Backend reconciliation at scale
Because there was no equivalent bulk-read primitive for all cloud providers, we used filtered list APIs in controlled batches to keep state consistent.
Insight 3: Long-Tail Paths Become First-Class at Scale
In non-bulk paths, the old flow made 3 API calls to fetch instance details. We reduced that to 1 call and got roughly a 3x speedup for that path.
This might seem minor in isolation, but during a burst event where retries are high, this change kept the system performant.
Insight 4: Database Efficiency Matters as Much as Compute
At high provisioning rates, DB connections can become the limiting resource even if VM creation is fast.
Connection pooling
We tightened connection pooling in workspace service to reduce churn.
Batch updates
Instead of one-by-one updates, we introduced bulk update queries for state, workspace runtime data fields in batches. This significantly lowered both connection count and write overhead.
Insight 5: Throughput Is End-to-End, Not Just Infra
Provisioning is only complete when repo bootstrap is done, so this path had to scale too.
What we changed:
- Right-sized node pools and service replicas for git service
- Switched setup to a single atomic push to git service instead of multiple round trips
- Applied git repack configuration to reduce NFS IOPS
- Load-tested NFS mount options and tuned for lower metadata operation pressure
- Adopted regional NFS in production and prepared migration plan
These changes prevented repo setup from becoming the next bottleneck after VM scaling improvements.
Insight 6: Load Tests Are a Design Tool, Not a Final Checkbox
We ran JMeter tests against production-like conditions to validate:
- 25,000 workspace provisioning capacity in one region
- ~1,000 assignments per minute sustained
Load testing was not just pass/fail. It helped us find hidden coupling and tune retry/backoff behavior before rollout.
Outcomes
The combined work took us from 5K to 25K workspaces per region while maintaining stability.
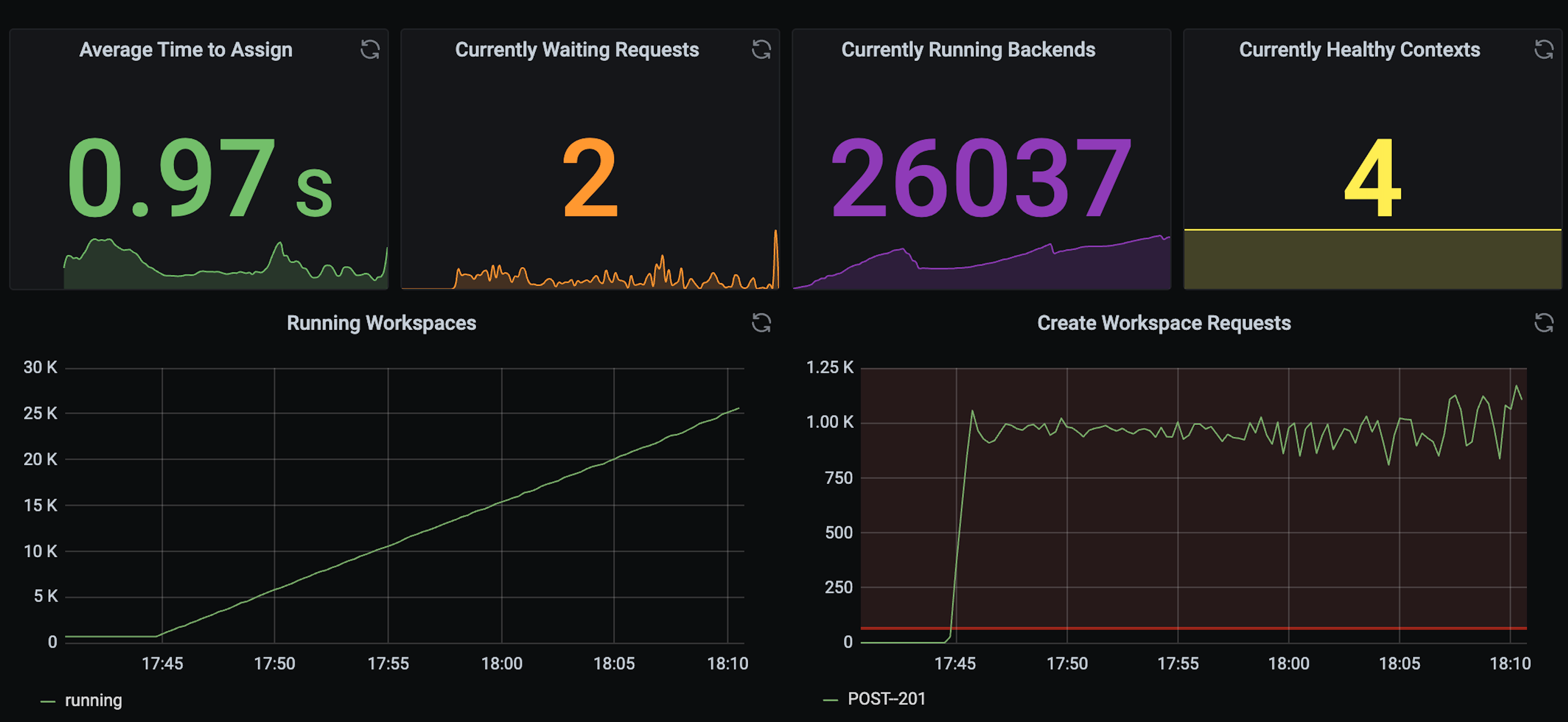
Results:
- 5x increase in per-region provisioning capacity
- Lower control-plane overhead through bulk operations
- Reduced DB pressure and better worker efficiency
- Better repo reliability under burst traffic
- Confidence through full-system load validation
What This Reinforced for Us
- Scale is a systems problem, not a VM problem.
- Bulk primitives become mandatory after a certain threshold.
- Long-tail paths matter more than most teams expect.
- If you do not test like production, production will test you.